
By Northhaven Analytics Technical Team
Introduction: The Data Paradox in Modern Enterprise
Data is often called the „new oil” in our digital age. However, for Chief Data Officers (CDOs) in regulated sectors, real-world data is different. It is more akin to uranium. It is powerful, yet radioactive. Handling it requires heavy protective gear. You need large compliance teams. Furthermore, you need strictly controlled environments. The risk of catastrophic leaks is always present.
This paradox creates a hold on innovation. Institutions possess petabytes of information. Yet, they cannot easily use it. Their ability to leverage it for advanced finance data analytics is limited. Similarly, healthcare analytics consulting faces hurdles. Privacy laws like GDPR and HIPAA constrain them. Strict internal frameworks, such as SR 11-7 in banking, also block progress.
This guide explores a solution. We discuss custom-built Synthetic Data Generators (SDGs). These tools dismantle barriers. We will examine synthetic data artifacts. These are dedicated Machine Learning models. They replicate statistical reality without PII. Consequently, they are revolutionizing industries. This includes banking, retail analytics solutions, and logistics and supply chain analytics.
Part 1: Redefining Finance Data Analytics with Synthetic Reality
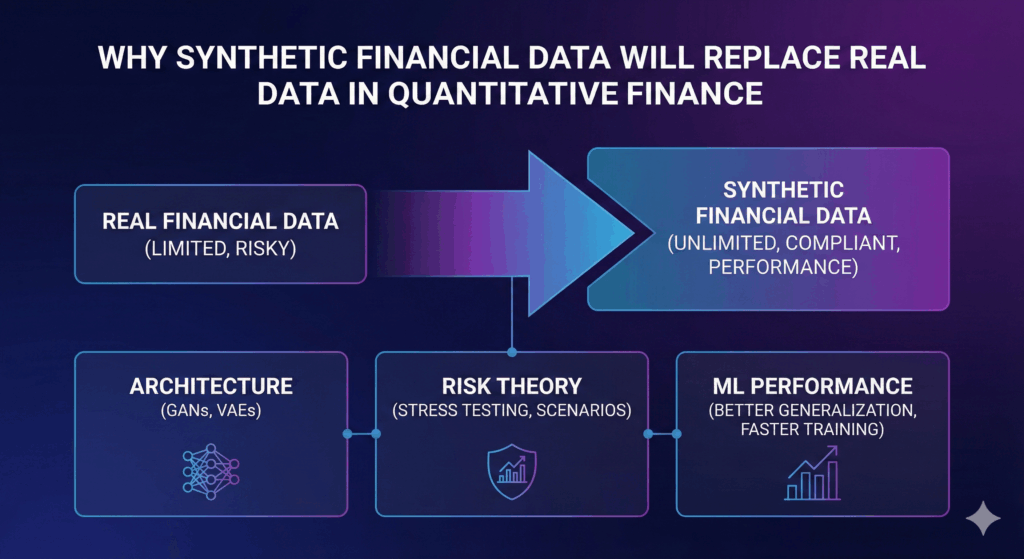
The Compliance Wall in Financial Services
The finance sector is paralyzed. There is a tension between innovation and regulation. Modern finance data analytics demands granular data. You need transactional-level details. This trains Deep Learning models for credit scoring. It also aids fraud detection. Yet, this data is the hardest to access.
Legacy techniques often fail. Methods like tokenization destroy correlations. These non-linear correlations are required for high-fidelity modeling. Therefore, if you mask a dataset too heavily, you lose the signal. Conversely, if you mask it too lightly, you risk re-identification.
The Northhaven Approach: Dedicated ML Artifacts
Northhaven Analytics solves this problem. We move away from „anonymization” entirely. We do not clean data. Instead, we learn it. Our approach to finance data analytics is unique. We train a dedicated Generative Adversarial Network (GAN). Alternatively, we use a Variational Autoencoder (VAE). This happens on the client’s secure infrastructure.
Once trained, this model becomes an artifact. It contains the statistical „soul” of the data. However, it contains none of the actual records. This allows banks to achieve three goals:
- Share Data Across Silos: You can create a synthetic replica of retail transaction data. Then, share it freely with the quantitative research team. This bypasses months of internal compliance approval.
- Validate Models Safely: Validation teams can stress-test algorithms. They can use billions of synthetic rows. Crucially, they never touch production PII.
- Collaborate Externally: Financial institutions can finally engage with third-party vendors. They can send synthetic datasets to cloud providers. These datasets are mathematically identical to internal data. Yet, they are legally distinct.
This represents a paradigm shift. It is the breakthrough that finance data analytics has been waiting for.
Part 2: Beyond Banking – Retail Analytics Solutions for the Privacy-First Era
Finance leads the charge. However, the retail sector faces a similar crisis. Modern retail analytics solutions rely on hyper-personalization. Brands must understand the exact customer journey. This spans from the first click to the final purchase.
The Death of the Cookie and the Rise of First-Party Data
Third-party cookies are phasing out. Scrutiny on consumer tracking is increasing. Therefore, retailers are forced to rely on first-party data. Analyzing this data carries risk. Reputational damage is a real threat.
Synthetic data offers a robust alternative. It powers safe retail analytics solutions. We generate synthetic customer profiles. These mimic real purchasing behaviors. They also replicate churn probabilities. As a result, retailers can:
- Train Recommendation Engines: Develop powerful models. These work on synthetic user bases. They are 100% representative of real shoppers.
- Simulate Market Shocks: Imagine a sudden 20% price hike. How would it affect loyalty? Synthetic simulations allow retailers to test this. They can check pricing elasticity in a risk-free sandbox.
- Share Data with CPG Partners: Retailers can monetize data assets. They sell synthetic insights to Consumer Packaged Goods (CPG) partners. This does not violate customer trust.
Northhaven uses temporal sequence modeling. This ensures that retail analytics solutions capture nuances. We track not just what was bought. We capture the sequence and timing of purchases. Thus, we preserve the integrity of the customer lifecycle.
Part 3: Healthcare Analytics Consulting – Saving Lives without Risking Privacy
Healthcare has a moral imperative to share data. Yet, patient privacy is paramount. Healthcare analytics consulting firms struggle with access. They need longitudinal patient records. These help develop predictive models.
The Problem with De-identification in Healthcare
Studies reveal a danger. „De-identified” health records are vulnerable. They can be re-identified using simple demographic cross-referencing. This liability freezes innovation.
The Synthetic Prescription
Northhaven applies financial rigor here. We bring our modeling expertise to healthcare analytics consulting. We model the lifecycle of a loan. Similarly, we model the „lifecycle” of a treatment pathway.
- Clinical Trial Simulation: We generate synthetic control arms. These augment small clinical trial populations. Consequently, this accelerates drug development.
- Rare Disease Modeling: Generative models can „oversample” rare conditions. We create large-scale datasets. These cover diseases that are scarce in the real world.
- Interoperability: Synthetic data connects disparate systems. Hospitals can benchmark performance. They share insights without legal hurdles. There is no transfer of PHI (Protected Health Information).
We enable healthcare analytics consulting teams. They work with high-fidelity synthetic records. This unlocks speed in medical research. Simultaneously, it keeps patient identities under lock and key.
Part 4: Logistics and Supply Chain Analytics in a Volatile World
The global supply chain is opaque. It is a web of proprietary data. Manufacturers and shippers are hesitant. They do not share inventory levels. Routes remain secret due to competition. This lack of transparency hurts logistics and supply chain analytics.
Creating the Digital Twin of the Supply Chain
Synthetic data creates a „Digital Twin”. We replicate the entire supply chain network and synthesize data on shipment delays. We also model port congestion. Companies can then run powerful logistics and supply chain analytics. They do this without revealing trade secrets.
- Scenario Planning: What if a major port closes for two weeks? Synthetic stress testing helps. It simulates thousands of disruption scenarios. This builds resilience.
- Fraud Detection: Fraud often hides in anomalies. Synthetic data trains ML models. They spot irregular shipping patterns. We generate vast quantities of „adversarial” fraud examples. These rarely exist in historical data.
- Collaborative Optimization: A manufacturer and a logistics provider can collaborate. They train a joint optimization model on synthetic data. This merges their operational realities. Yet, they never exchange proprietary databases.
Northhaven models multi-agent interactions. This makes us uniquely suited for logistics and supply chain analytics.
Part 5: The Technical Core – How It Works
Northhaven’s platform is robust. It is not a simple script., but t is a deep learning architecture. It is designed for enterprise rigor.
1. The C-CTGAN / TSM Hybrid
We utilize a modified architecture. It is a Conditional CTGAN. The „Conditional” aspect gives users control. For example, you can „Generate 10,000 high-net-worth individuals”. We couple this with a Temporal Sequence Model (TSM). This ensures time-series data maintains causal consistency.
2. Privacy by Design
Our training process is secure. We incorporate Differential Privacy (DP) mechanisms. We clip gradients during training. This ensures the model learns general distributions. It does not memorize outliers. This creates a mathematical guarantee of privacy.
3. Automated Fidelity Metrics
We verify every dataset. Whether for finance data analytics or healthcare analytics consulting, quality matters. Our system outputs a Validation Report. This includes:
- Kullback-Leibler (KL) Divergence: This measures the distance between distributions.
- Pairwise Correlation Matrices: These ensure relationships between variables are preserved.
- Discriminator AUC: This verifies realism. An ML model cannot distinguish synthetic rows from real ones.
Conclusion: The Synthetic Advantage
Liquid data wins. Organizations with accessible data will lead the next decade.
Consider optimizing capital reserves via finance data analytics. Or, personalize shopper journeys with retail analytics solutions. Perhaps you are advancing research through healthcare analytics consulting. Maybe you are hardening networks with logistics and supply chain analytics. The bottleneck is no longer technology. It is access.
Northhaven Analytics provides the key. We decouple data utility from data privacy. We empower enterprises to innovate. You move at the speed of software. You are no longer slowed by compliance.
Ready to transform your data infrastructure? Explore our dedicated generative solutions at www.northhavenanalytics.com.
