By Northhaven Analytics Research Team
Introduction: Why the Future of AI Depends on Synthetic Data
In the rapidly evolving landscape of artificial intelligence, a critical bottleneck has emerged: data is scarce. While the world generates petabytes of information daily, high-quality, privacy-compliant data to train sophisticated models is often locked behind regulatory walls or simply does not exist in sufficient quantities.
This is where synthetic data emerges as the definitive solution.
Synthetic data is generated information that mirrors the statistical reality of the physical world without containing any direct record of it. Unlike real data, which is collected from actual events, synthetic data is artificially generated by advanced algorithms. It allows organizations to create synthetic assets that function as a digital twin of their original information.
In this definitive guide, we explore the benefit of synthetic data, how generative AI creates it, and why data scientists across finance, healthcare, and logistics are pivoting to this technology to solve the „Data Rich, Information Poor” paradox.

What is Synthetic Data? Defining the New Standard
At its core, synthetic data is artificial data that is manufactured rather than collected. However, calling it „fake” is a misnomer. High-quality synthetic data retains the statistical properties of real data—the correlations, distributions, and structures—making it mathematically identical to the source for analytical purposes.
When original data is scarce or too sensitive to share, synthetic data can be generated to fill the gap. It allows enterprises to use data that is compliant by design.
How Synthetic Data is Created
The process to produce synthetic data involves complex machine learning architectures. We do not just randomize spreadsheets; we generate data that learns the „soul” of the original dataset.
- Generative Adversarial Networks (GANs): This is a popular method where two neural networks compete. One network is used to generate synthetic samples, while the other acts as a critic. The interaction between synthetic data and a discriminator ensures that the generated data is indistinguishable from the real thing.
- Variational Autoencoders (VAEs): This architecture compresses input data into a lower-dimensional latent space and then reconstructs new data from that compressed representation. This allows us to generate synthetic records that possess the same underlying characteristics as the source.
By using real data to train these generative models, we ensure that the output mimics real-world data with high fidelity.
The Types of Synthetic Data
Not all synthetic data is the same. Depending on the use case, data scientists may deploy different types of synthetic data:
1. Fully Synthetic Data
This synthetic dataset contains entirely new data. No record in the data set corresponds to a real person. Fully synthetic data offers the highest level of data protection because it breaks the link between the data subject and the data record. It is ideal for external sharing and cloud migration.
2. Partially Synthetic Data
Sometimes, you need to preserve actual values (e.g., real zip codes or transaction timestamps) while synthesizing sensitive attributes (e.g., income). In this scenario, partially synthetic data is used. Here, partially synthetic data replaces only the sensitive columns with new data points, leaving the rest intact.
3. Hybrid Synthetic Data
Hybrid synthetic data combines real and synthetic records to blend the privacy benefits of synthetic data and original data. This is often used when data is crucial for referencing specific historical events while expanding the dataset size.
The Benefit of Synthetic Data for AI Training and Testing
The primary use of synthetic data today is in AI training. Modern deep learning models are data-hungry. Real-world training data is often messy, biased, or expensive to label.
Synthetic data helps overcome these limitations by providing:
- Access to High-Quality Data: We can programmatically improve data quality by fixing errors and filling gaps during generation.
- Balancing Datasets: If data is scarce for a specific event (e.g., fraud), we can create synthetic data to oversample these rare instances.
- Robust Test Data: Engineers need test data that pushes models to their limits. Synthetic data can be used to simulate „edge cases”—scenarios that haven’t happened yet but might.
Because synthetic data is generated on-demand, it provides an unlimited supply of training data for data science teams.
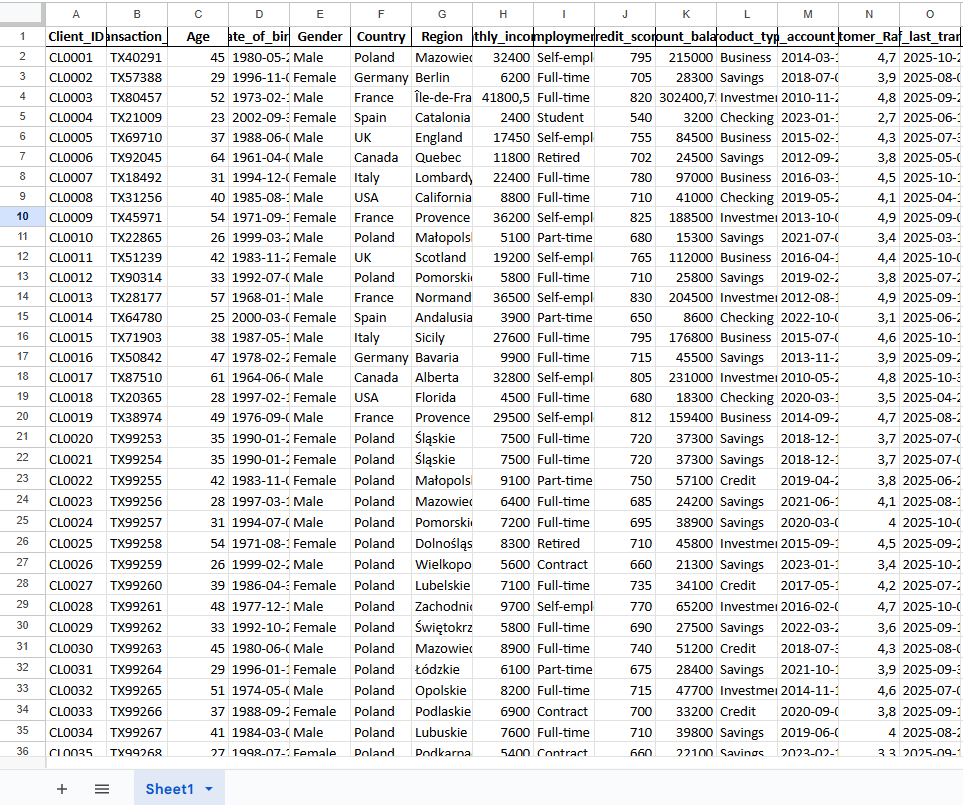
Synthetic Data in Finance: Tabular and Time Series
In the financial sector, tabular data (rows and columns of transactions) and time series data (stock prices, account balances over time) are king.
Northhaven Analytics specializes in creating synthetically generated data that respects the temporal dynamics of finance. Synthetic data can also capture complex, non-linear relationships, such as how a credit score evolves over 60 months.
By creating a synthetic data vault—a secure repository of generative models—banks can generate new data for liquidity stress testing without touching production servers. This synthetic data use case enables compliance with regulations like SR 11-7 without the operational friction of anonymizing sensitive data.
Privacy and Compliance: Why Synthetic Data Eliminates Risk
The use of synthetic data is a game-changer for privacy. Traditional anonymization (masking) often fails because actual data synthetic data comparisons can lead to re-identification.
Synthetic data eliminates this risk. Since the data generated does not relate to a specific individual, it is generally considered non-personal data under GDPR. This means synthetic data may be shared freely across borders, accelerating innovation.
Synthetic data can help organizations:
- Work with synthetic data in public cloud environments (AWS, Azure) safely.
- Use synthetic data for third-party vendor validation.
- Train models on data without exposing personal data.
When data privacy is the priority, ai-generated synthetic data is the only viable path forward.
Comparison: Synthetic Data vs. Real Data
Why should you generate synthetic data instead of using what you have?
| Feature | Real Data | Synthetic Data |
| Availability | Data is scarce, hard to access. | Unlimited, generated on demand. |
| Privacy | High risk, contains PII. | Privacy safe, fully synthetic data. |
| Cost | Expensive to collect and label. | Low marginal cost to generate data. |
| Edge Cases | Limited to historical events. | Can create synthetic edge cases. |
| Utility | Original data may be messy. | High-quality data structured for ML. |
It creates generated data that mimics real-world complexity but allows for greater control. Synthetic data represents the original data statistically, but offers operational freedom.
Advanced Applications: Synthetic Text and Images
While Northhaven focuses on finance, synthetic data generators are transforming other fields.
- Synthetic Image: Used to train autonomous vehicles (e.g., generating synthetic pedestrians).
- Synthetic Text: Large Language Models (LLMs) often use synthetic text to fine-tune their capabilities without ingesting copyrighted or sensitive documents.
Whether it is synthetic image recognition or financial forecasting, the principle remains: input data into a lower-dimensional understanding and output unlimited, high-utility assets.
Conclusion: The Future is Synthetically Generated
The era of relying solely on existing data is ending. Data is crucial for the AI economy, but the barriers to accessing real-world data are too high.
Synthetic data is also an infrastructure play. It provides the data points necessary to build robust AI models while navigating a complex regulatory landscape. By leveraging generative AI to produce synthetic data, institutions can ensure data protection while maximizing data utility.
Synthetic data helps overcome the scarcity, privacy, and bias issues that plague modern data science. Whether you need data to create a new credit model or data to aid in fraud detection, the answer lies in the synthetic dataset.
At Northhaven Analytics, we don’t just mimic real-world data; we engineer the future of financial intelligence.