By Northhaven Analytics Strategy Team
Introduction: Data as a Liability vs. Data as an Asset
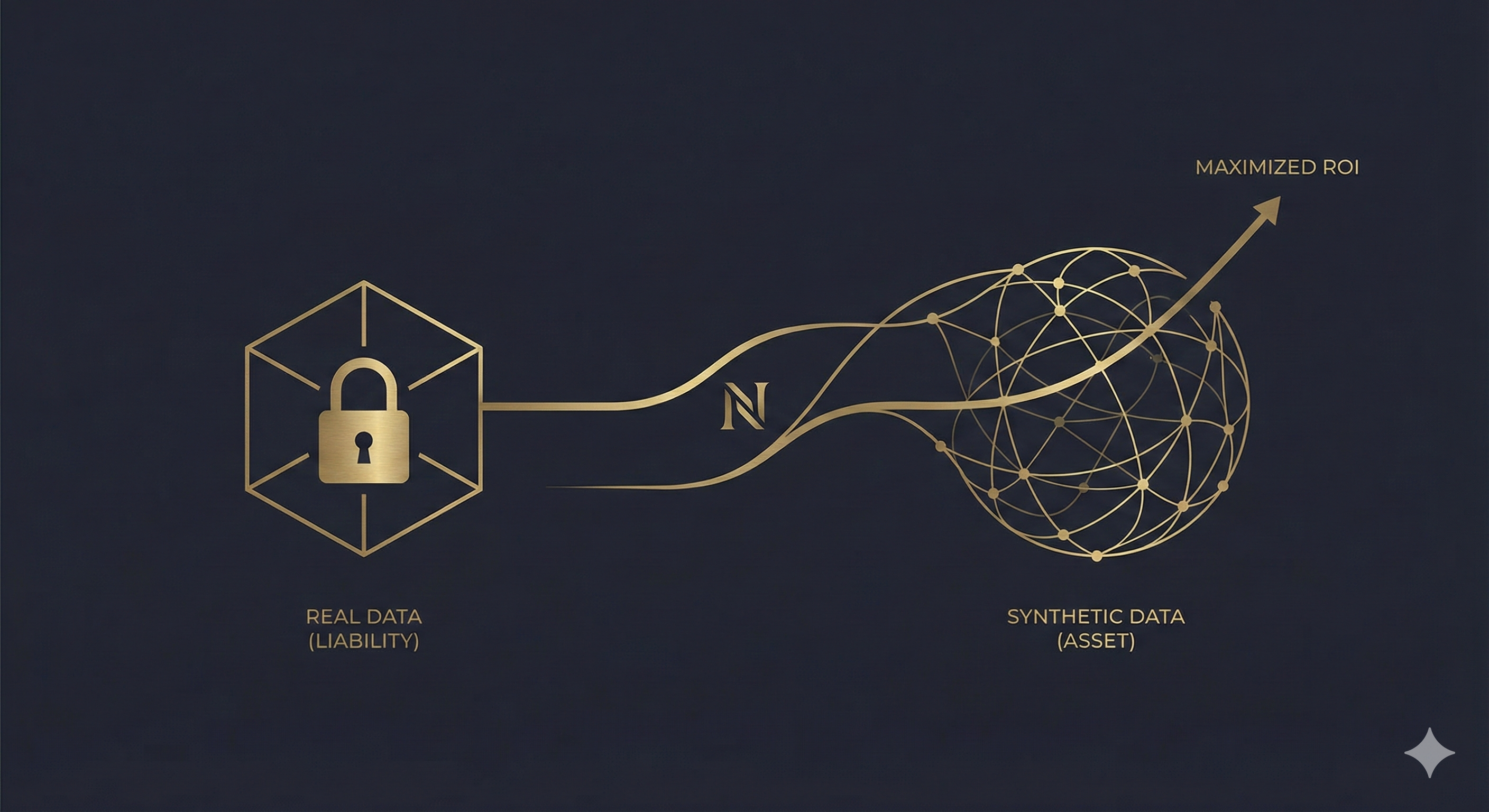
In the ledger of a modern bank, client data sits in a strange superposition. It is theoretically the institution’s most valuable asset—the fuel for AI, personalization, and risk scoring. Yet, operationally, it behaves like a toxic liability.
Storing, moving, and using real client data incurs massive costs: legal reviews, encryption overhead, access controls, and the looming threat of GDPR fines.
This friction creates a hidden tax on innovation. Data Science teams spend 80% of their time waiting for data access and only 20% building models.
Financial Synthetic Data flips this equation. By decoupling the statistical value of data from the identity of the customer, it transforms data from a protected liability into a liquid, unlimited asset.
In this guide, we analyze the Return on Investment (ROI) of adopting Financial Synthetic Data infrastructure.
What is Financial Synthetic Data?
Before calculating ROI, we must define the asset. Financial Synthetic Data is artificially generated information that mirrors the statistical properties of real-world financial records—transactions, credit histories, loan applications—without containing any Personally Identifiable Information (PII).
Unlike „anonymized” data, which is merely real data with the names hidden (and thus still risky), Financial Synthetic Data is created from scratch by generative Machine Learning models. It is mathematically new data that behaves exactly like the old data.
The 3 Pillars of ROI for Financial Synthetic Data
Why are Tier-1 banks and leading Private Debt funds investing in synthetic infrastructure? The business case rests on three pillars: Speed, Cost, and Quality.
1. Velocity: Reducing Time-to-Data from Months to Minutes
In a traditional banking environment, getting a production-grade dataset for a new ML project can take 3 to 6 months due to compliance checks.
- The Synthetic Advantage: Once a Northhaven Analytics model is trained, it can generate Financial Synthetic Data on demand. Developers can access a sandbox dataset in minutes.
- ROI Metric: If a Data Science team costs $2M/year and spends 6 months waiting for data, the „Idleness Cost” is $1M. Synthetic data recovers this lost value immediately.
2. Compliance Cost Reduction
The cost of compliance is skyrocketing. Anonymizing data for external sharing (e.g., with cloud providers or fintech partners) is an expensive, manual process that often degrades data quality.
- The Synthetic Advantage: Financial Synthetic Data falls outside the scope of GDPR (Recital 26). It can be shared freely across borders and with third parties without complex legal frameworks.
- ROI Metric: Elimination of third-party data scrubbing fees and reduction in legal billable hours for data sharing agreements.
3. Model Performance and „Data Economics”
Real data is often „expensive” in terms of quality—it is messy, missing values, and biased against rare events (e.g., fraud).
- The Synthetic Advantage: We can programmatically improve Financial Synthetic Data. We can balance classes (e.g., generate more fraud cases), fill in missing gaps, and simulate future economic scenarios.
- ROI Metric: Better trained models lead to lower default rates and higher fraud detection accuracy. A 1% improvement in a credit scoring model can equal millions in saved capital.
Technical Superiority: Why Generic Data Fails
Not all synthetic data is created equal. Low-quality synthetic data (random noise) has a negative ROI because it leads to bad business decisions.
To achieve high ROI, Financial Synthetic Data must be engineered with domain-specific architecture.
The Northhaven Standard
At Northhaven Analytics, we utilize a C-CTGAN (Conditional Generative Adversarial Network) architecture reinforced with Temporal Sequence Modeling.
- Why it matters: Financial data is time-dependent. A transaction today influences a credit score tomorrow. Generic tools miss this. Our engine captures the causal chain of financial events, ensuring that the synthetic data is robust enough for complex Risk Management and Liquidity Stress Testing.
Strategic Use Case: The Cloud Migration Accelerator
The most immediate ROI for Financial Synthetic Data is often found in cloud migration strategies.
Banks want to leverage the immense compute power of public clouds (AWS, Azure, Google Cloud) to train Large Language Models (LLMs) or complex risk engines. However, internal security policies forbid uploading real customer PII to the public cloud.
The Solution:
- Train a Northhaven Generative Model on-premise (inside the bank’s firewall).
- Generate a massive Financial Synthetic Dataset.
- Upload the synthetic data to the public cloud.
- Train the AI models using cheap, scalable cloud compute.
- Download the trained model back to the bank.
This workflow enables banks to use cutting-edge cloud tech without ever exposing a single real customer record.
Conclusion: The Cost of Doing Nothing
Financial Synthetic Data is no longer an experiment. It is the infrastructure of the AI-native bank.
Ready to calculate your ROI? See how Northhaven Analytics can transform your data infrastructure.